Det är dags igen! Välkommen att samverka i framtidens community! Nu arrangerar vi tredje upplagan av Open Space: Digitalisering, kompetensförsörjning och livslångt lärande den 1–2 juni i Stockholm.
Enheten Jobtech på Arbetsförmedlingen och Sunet arrangerar en serie workshops i Open Space-format, som arbetsform för delar av regeringsuppdraget om en sammanhållen datainfrastruktur för kompetensförsörjning och livslångt lärande.
Den 1–2 juni arrangerar vi workshop nummer 3, och vi välkomnar alla inom såväl offentlig som privat sektor att delta och bidra med insikter, förslag och tankar. Vi vet att samverkan ger konkreta resultat.
Skicka gärna inbjudan vidare!
Har du kollegor eller andra kontakter som kan vara intresserade av att delta, bjud gärna in dem också. Vi behöver både dina och andras kloka insikter, förslag och tankar för ett event som genererar nytta och värde för alla.
Plats och tid
Eventet kommer att äga rum under två dagar, den 1–2 juni, på plats i Stockholm i Internetstiftelsens lokaler, Hammarby Kaj 10D.
Anmälan
Anmäl dig och läs mer om eventet.
Vi hoppas att vi ses där.
Välkommen!
Läs gärna sammanfattning och anteckningarna här.
A summary in English is available here.
Jag var med på ett seminarium och har tidigare ställt frågan på GITLAB hur jobbar ni med metadata och rent konkret LLM - Hur jobbar projektet med ESCO ontologin? Är ni del av att utveckla den eller en svensk motsvarighet och var sker dialogen och vem använder den idag i Sverige.
Lyssnade även på DIGG i veckan och dom bygger inga ekosystem se #76 " Ett Ekosystem måste skapas så att det går att ta ut statistik och jämföra kommuner/myndigheter/museer" där dom inte vet vem som använder vilket data och det är nog värre än så då det aldrig pratas om Persistenta identifierare…
Samverkan tolkas udda
På mötet svamlades det av DIGG och nedan snackar Maria om att ladda upp på dataportalen MEN utan Persistenta Identifierare och koppla samma som blir detta data mest trams… dålig data blir inte bättre av att det laddas upp på massa platser
- lägger man alla legobitarna i samma portal så är dom fortfarande inte ihopkopplade dvs. 5 star data = arranged
Min take
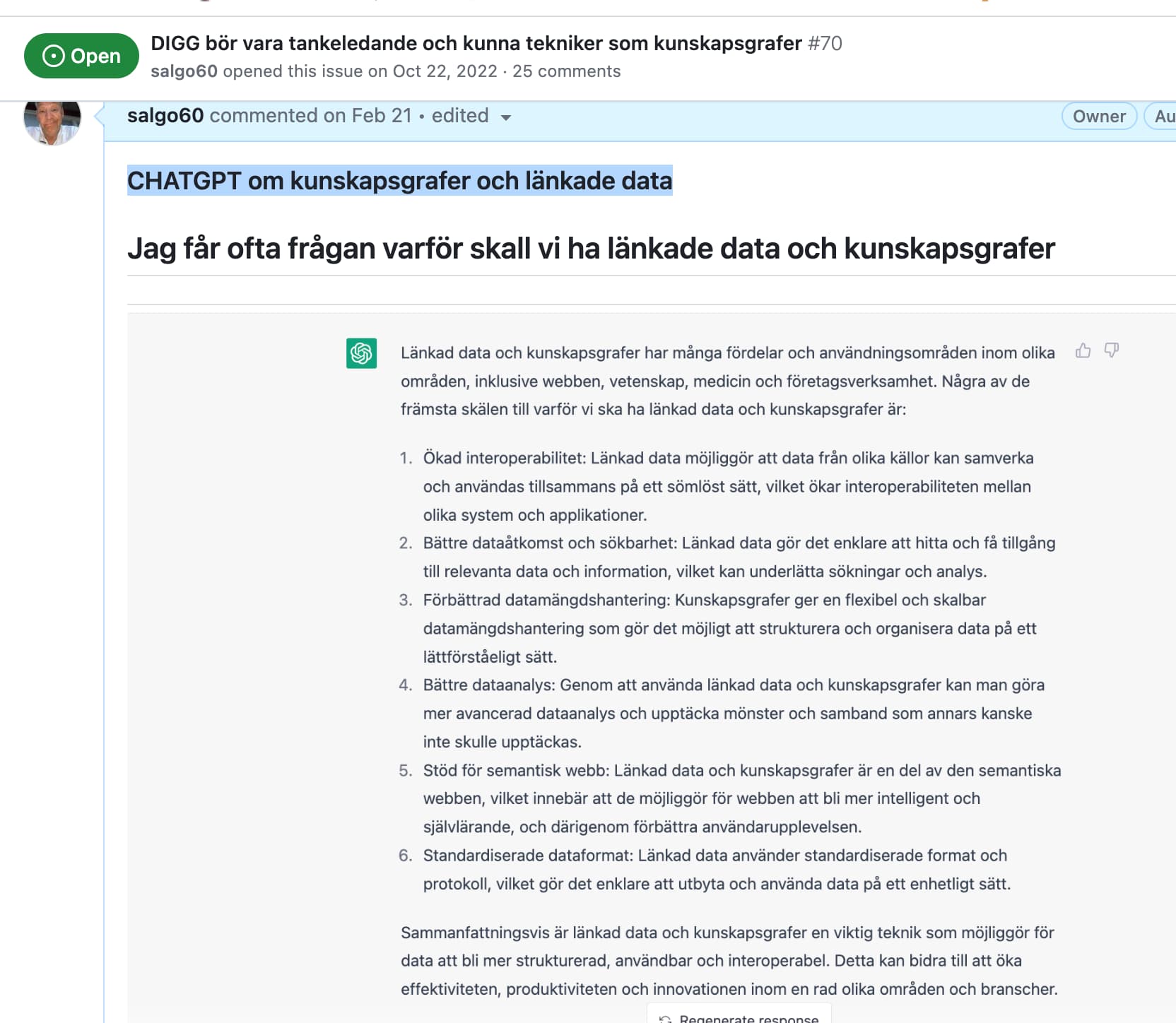
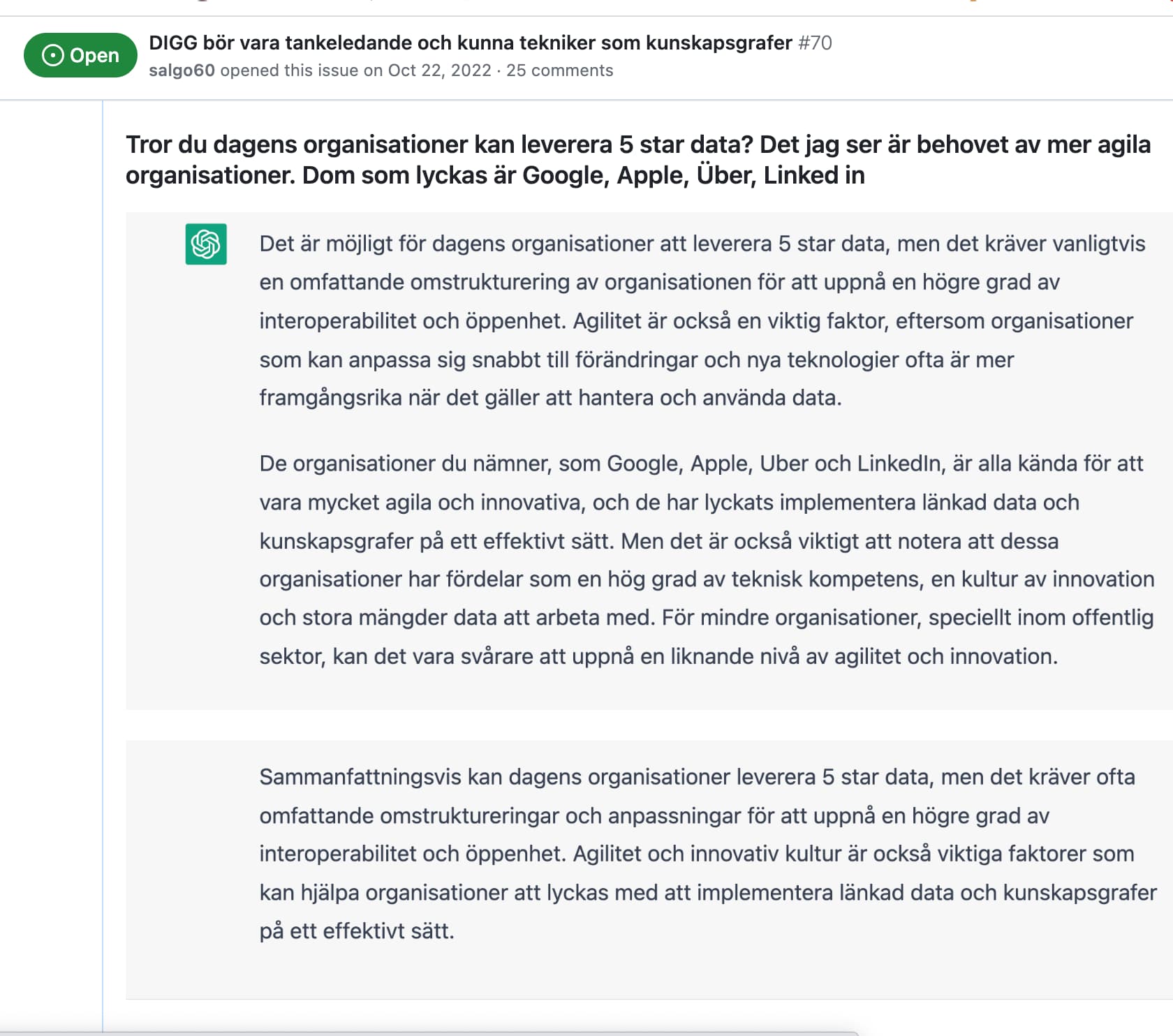
Skall ni jobba med data måste ni ha folk som kan data… Mannen från SCB på mötet imponerade inte och när vi snackade efteråt så visste han inte vad en kunskapsgraf är. Det blir inte bra och ni sitter och hittar på massa egna termer man behöver inte uppfinna hjulet i varje projekt se vad chatGPT säger om “kunskapsgrafer och länkade data”
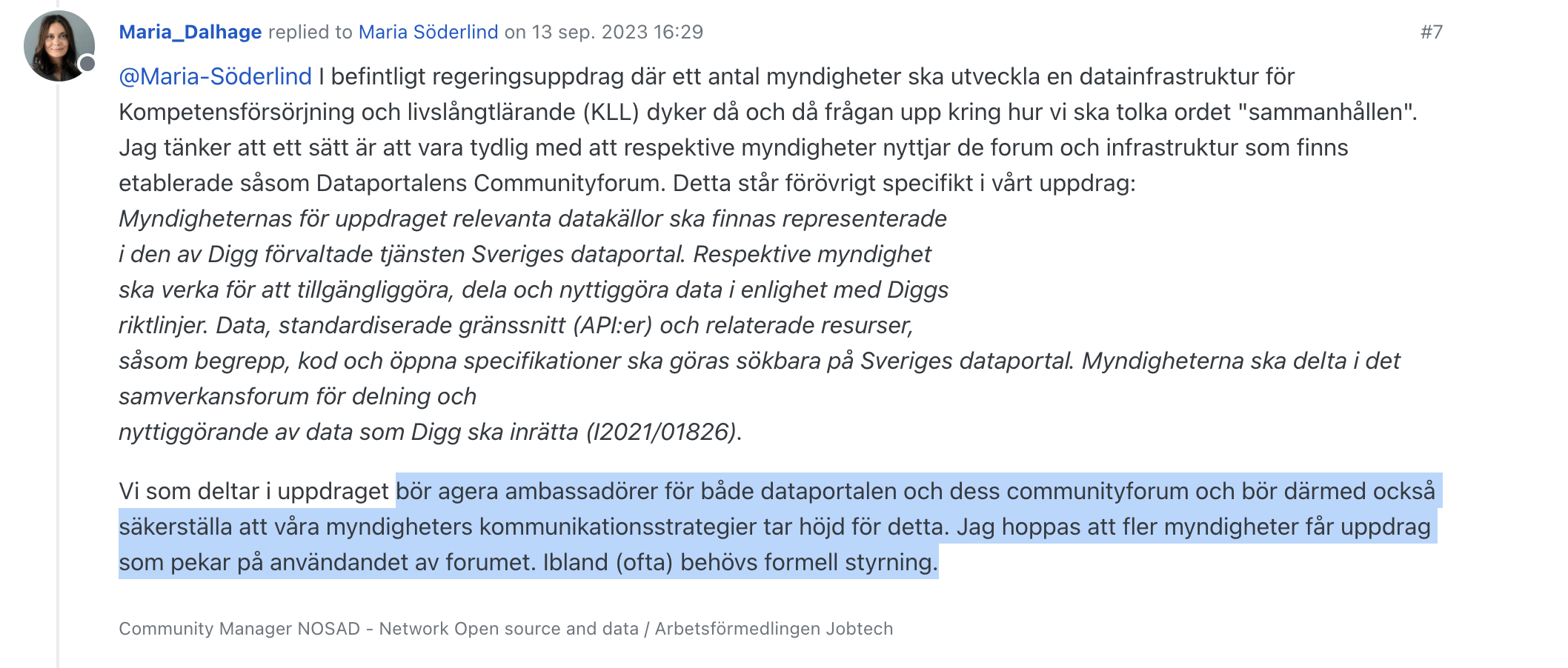
@salgo60 Känner mig manad att svara då mitt namn finns med i inlägget. Du undrar hur vi arbetar med ESCO ontologin. Vidare ställer du frågan: Är ni del av att utveckla den eller en svensk motsvarighet och var sker dialogen och vem använder den idag i Sverige.
ESCO förvaltas av EU-kommissionen och de ansvarar också för översättningar till svenska. De samlar in åsikter och kommentarer från arbetsförmedlingar i medlemsländerna, branscher, företag, utbildningsanordnare med flera (Contact | ESCO (europa.eu)). Alla medlemsländer är också ålagda att antingen använda ESCO eller kartlägga relationen mellan begrepp i ESCO och begrepp i den nationella arbetsmarknadstaxonomin. Det är vårt ansvar. Relationen mellan begrepp i ESCO och begrepp i den nationella taxonomin går att se i vår Atlas (JobTech Atlas (jobtechdev.se)). I Sverige används vanligtvis inte ESCO direkt. Det som förekommer är att den kartlagda relationen mellan begrepp i ESCO och begrepp i den nationella taxonomin används i till exempel överföring av jobbannonser till EURES eller i försök att identifiera ”gröna” eller ”digitala” kompetenser. Det här har du nog redan bra koll på eftersom du har undersökt taxonomin tidigare. 
Tackar @Mariadalhage den intressanta frågan är hur får vi in LLM = WD Q115305900 ? Jag hittar inte det i svenska eller i ESCO? (jmf med versionshistoriken på engelsk wikipedia)
Det jag ser:
- LLM kommer att förändra vilka yrken som kan automatiseras så sent som i veckan kom nya spännande funktioner att Open AI will skapa motsvarande “app store” GPT Store → nya kompetenser skall definieras
- lyssnar man på nvidia chip grundaren så pratar han i termer om att alla företag kommer att ha sin egen AI modell med sitt företags “kompetens” - " NVIDIA to Bring AI to Every Industry, CEO Says"
dvs. dessa kompetenser som kan LLM kommer att förändra allt och det känns som en relevant fråga var kan jag se dessa kompetenser hos ESCO och i den svenska? att bara “efter överföring av jobbannonser” skall synas känns fel jag måste kunna se vilka jobbannonseringar som kopplas till vilka skills och i detta fall LLM relaterade skills…
Allt låter feldesignat:
a) det jag tycker mig ha sett
a-1) är att yrken bygger på en gammal “standard” SSYK som togs fram för att stödja löneförhandlingar inte för att stödja kopplingar till typ ESCO som ni verkar ha en egen logik för?
a-2) att jobtech gjort en Taxonomy och inte en kunskapsgraf “vilket alltid har känts fel” och ännu mer fel 2023 där det på eran kod borde kunna se koppling till ESCO och i detta specifika fall hur LLM beskrivs i ESCO ontologin och om Jobtech har en egen modell eller om det är SKOS exact match
begrepp i den nationella taxonomin används i till exempel överföring av jobbannonser till EURES eller i försök att identifiera ”gröna” eller ”digitala” kompetenser
a-3) Borde jag inte kunna söka jobbannonser i realtid med ESCO koder?
Allmän kommentar det kändes verkligen oldschool på seminariet att DIGG definierar hur man skall jobba så pratas det ladda upp på dataportalen men vad metadata var så blev det flummigt och när jag som sagt pratade med SCBs representant så hade vi inte samma begrepp
-
jag vill se tydliga flöden/processer och var jag hittar LLM i detta eller är det bara SSYK 2012 polis som finns med 
-
Se var i processen LLM befinner sig, och var tar det stopp
- nu finns persistenta identifierare i ESCO ontologin ange samma som och var en del av projektet med persistenta identifierare se spännande tankar av SND
-
det borde vara vettigt att se hur efterfrågan av LLM kompetens förändras över tid i Europa och hur skolorna ställer om. Jag har en grabb som pluggar masterprogrammet i hälsoinformatik på Karolinska Institutet de flesta av eleverna tittar på LLM men den känsla jag får är att den del som sköts av Karolinska Universitetet hinner inte med att ställa om till LLM utan det intressanta kommer från Stockholms Universitet
- min tro är att det behövs skapas en helhet av arbetsmarknaden i Europa och LLM och även vilka masters utbildningar som ställer om
- att då inte ens se LLM i ESCO eller svenska motsvarigheten känns fel… eller att jag kan följa var i processen vi är för att få in det känns fel 2023-nov…
Exempel hur snabbt USA agerar för att dra till sig kompetens och även peka på vilka olika visums möjligheter som finns
min oro att projekt som detta inte jobbar själva med persistenta identifierare länk utan det saknas informationsstruktur och informationen skapas av webdesigners…